eval_752 — 量化降智,LLM 定分枪
开源 · 自托管 · 本地优先
量化降智,LLM 定分枪
eval_752 是一套本地优先的大模型评测平台。把测试跑在自己的机器上,用同一套数据集横向对比不同提供商。大模型有没有悄悄变笨?有没有挂羊头卖狗肉?不要凭感觉,用数据和证据说话。
- 统一标准,跨端对比
- 统一接入任意兼容 OpenAI 格式的 API,用完全一致的工作流横向对比各家模型。
- 保留完整证据链
- 实际调用的模型名、网络重试记录、逐题响应切片,全部随运行结果打包定格。
- 用源码级证据说话
- 将结果导出为独立、可检查的
.eval752.zip文件,告别截图发群的粗放分享。
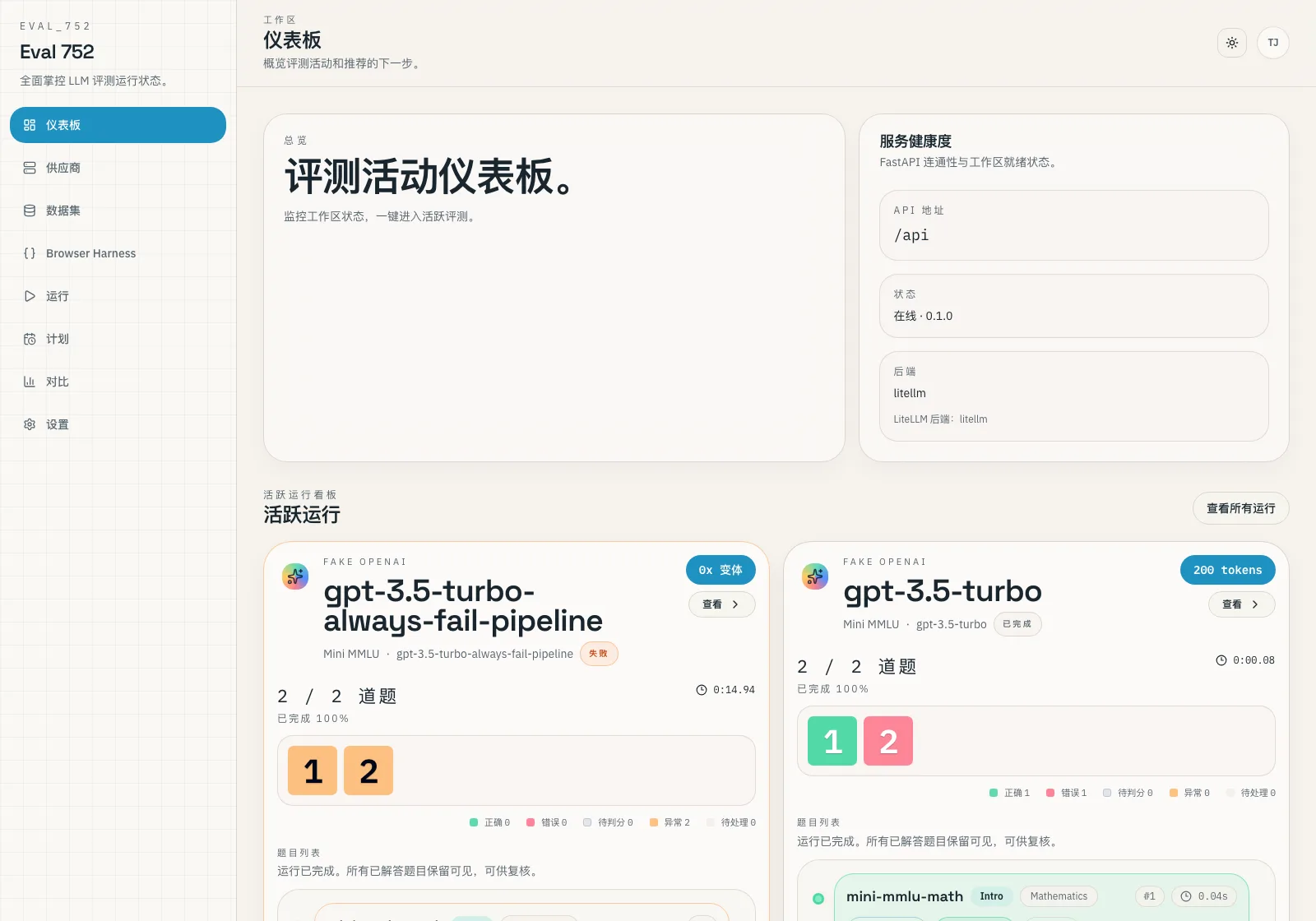
把活跃运行、最近结果和工作区健康状况放在同一个控制面里。
为什么要自己评测他们有能力造假,
他们有能力造假,
我们应该有能力核验。
大模型 API 通常是一个“黑盒”。厂商可以在不发布任何公告的情况下悄悄更换底层模型、降低推理算力来节省成本,甚至对高频用户做“静默降级”。当你感觉模型变笨时,你需要确凿的证据。
eval_752 将核验动作融入评测的基础流程中:在跑基准前先做连通性测试,记录确切的模型标识符;使用同一套提示词对比多家厂商;最后输出可供任何人复查和审计的评测包。
研究发现,第三方 API 提供的模型经常与宣称的不符——性能差距最高可达 47%,且在指纹验证中表现出大范围的身份不一致。
张等,2026 · Real Money, Fake Models
- 在这批 Token 真正花掉之前,先对保存的模型名做一次校验。
- 通过 Browser Harness,把只能在网页端使用的模型拉回同一套评分体系中。
- 设置自动化定时巡检任务,让模型的“暗中降智”以数据指标的形式出现。
工作流程
闭环、本地优先的评测工作流。
- 1配置 Provider。
填写 API 地址、保存真实的模型名,并完成连通性验证。
- 2选择数据集。
一键导入公开基准集、上传你自己的私有数据,或者带入浏览器端截获的对话。
- 3运行与审查。
实时观测执行进度,深度下钻单题日志,全面对比不同厂商的得分、延迟及开销。
- 4导出与监控。
导出包含完整证据链的结果包用于审计,或设定定时巡检任务随时捕捉模型退化。
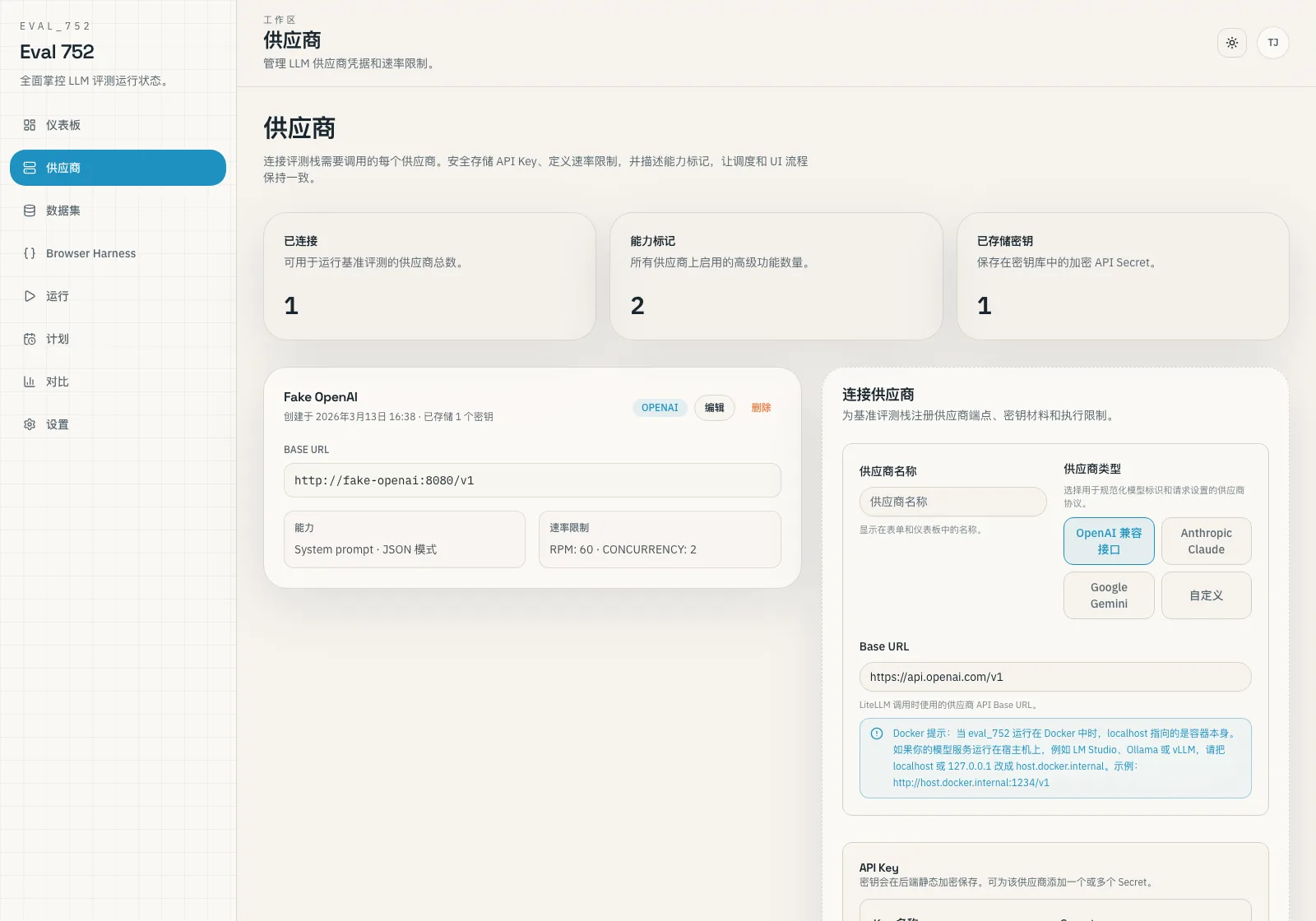
文档入口
各取所需的文档结构。
文档按阅读者的角色进行组织。如果你想尽快把系统跑起来并完成首次评测,请看“操作者”路径;如果你要进行二次开发、了解代码架构,请看“构建者”路径。
基于 Docker、FastAPI、React、PostgreSQL、Redis、Celery 与 LiteLLM 构建。我们更相信可复现的真实数据,而不是厂商的营销话术。