eval_752 — Local-first LLM Evaluation
Independently evaluate the LLMs you pay for.
eval_752 is a local-first platform to test, compare, and monitor LLM APIs. Run evaluations on your own infrastructure to catch silent model downgrades and test the LLMs you were actually served. Ever Felt off? Test them.
- Unified Testing Standard
- Route any OpenAI-compatible API through identical workflows for a true apples-to-apples comparison.
- Unbreakable Audit Trail
- Actual model names, network retries, and item-level latency stay attached to every single run.
- Reproducible Evidence
- Export self-contained
.eval752.zipbundles for independent review instead of sharing screenshots.
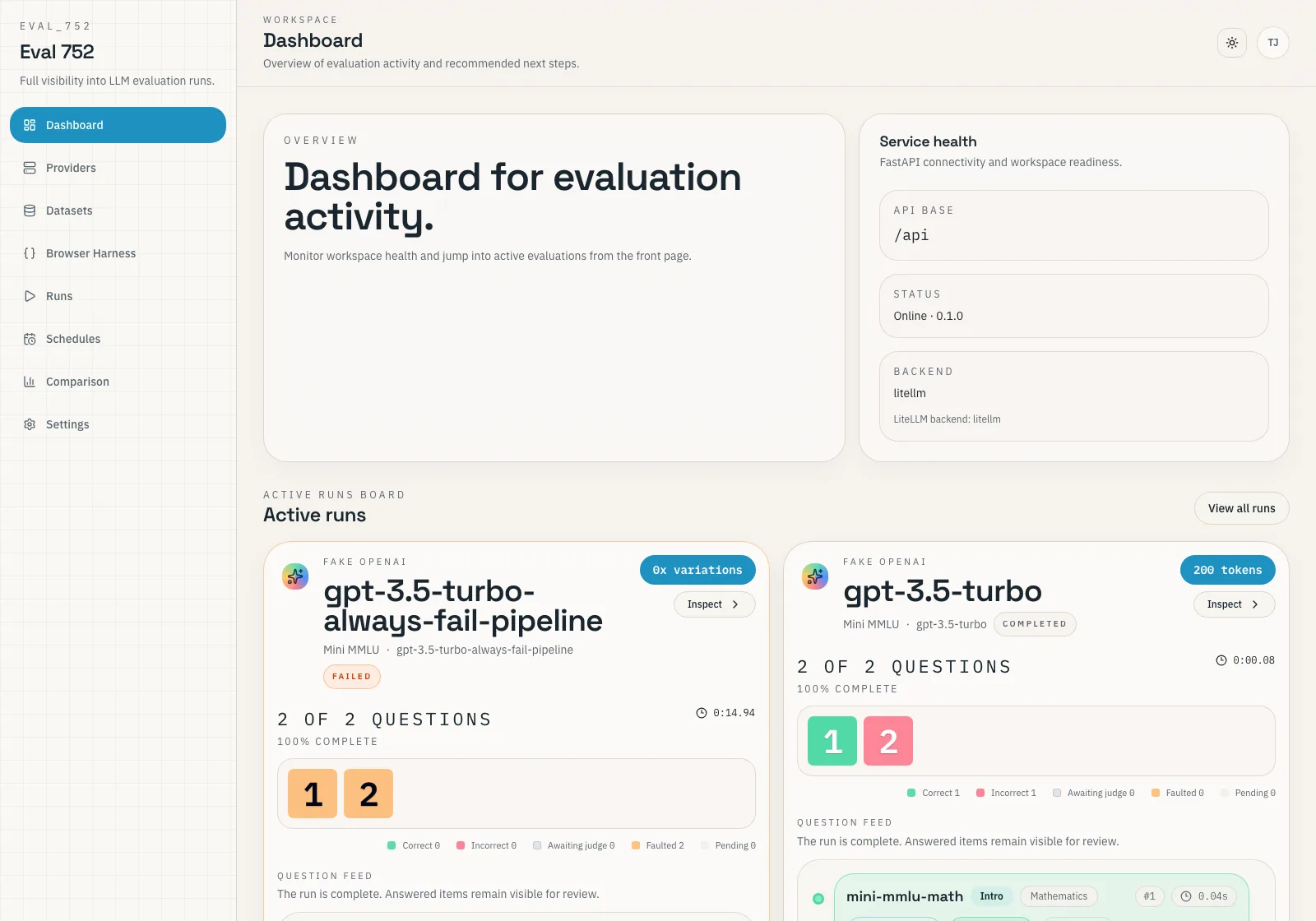
Keep active runs, recent results, and workspace health in one control plane.
They have the ability to lie. We should have the ability to check.
Third-party LLM APIs are moving targets. Providers can quietly swap models, reroute traffic, or reduce reasoning effort to cut costs without ever changing the product name. If you care about regressions or model identity, you need evidence you gathered yourself.
eval_752 keeps verification natively inside the benchmark workflow. Save the exact model name, smoke-test it, compare providers on identical prompts, and export reproducible bundles that you can verify later.
Research shows that third-party LLM APIs frequently serve different models than advertised — with performance gaps up to 47% and widespread failures in identity verification.
Zhang et al., 2026 · Real Money, Fake Models
- Smoke test the exact saved model name before spending tokens on serious runs.
- Pull browser-only models into the same scoring flow with Browser Harness.
- Schedule recurring runs so model regressions show up as hard evidence, not vibes.
A complete, local-first evaluation loop.
- 1Connect the provider.
Save the base URL, absolute model identifier, and verify with a smoke test before paying for tokens.
- 2Choose the dataset.
Import a Hugging Face benchmark, bring your own test suite, or score a browser-captured conversation.
- 3Run and inspect.
Watch live progress, investigate item-level failures, and compare cost, accuracy, and latency side-by-side.
- 4Export or schedule.
Archive a reproducible bundle for stakeholders, or set up recurring runs to catch silent API degradation.
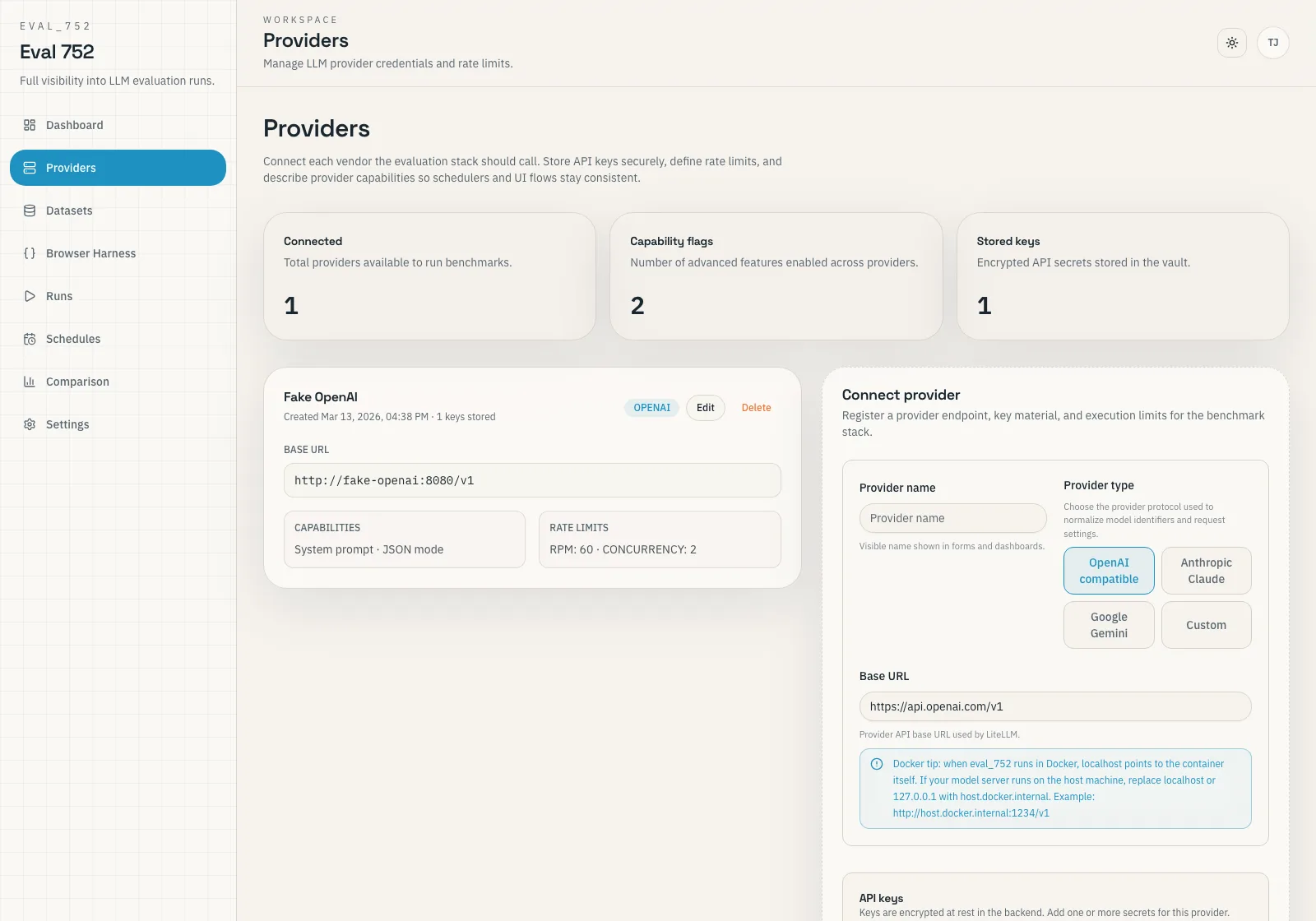
Find what you need.
The documentation is organized by role. Use the operator path to deploy the stack, hook up a provider, and finish your first run. Use the builder path when you want to understand our architecture or contribute code.
Built with Docker, FastAPI, React, PostgreSQL, Redis, Celery, and LiteLLM. Biased toward reproducible evidence over provider marketing.